![[통계] 중앙값, 중간범위, 평균, 최빈값, 범위, 표준편차, 정규분포, 편향, 분산](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbTjqnl%2FbtsKvaioOCa%2FJlIUdTLDHNwwdLkyRuIK4K%2Fimg.png)
기초 데이터
tmp = [ 75, 80, 100, 100, 100 ]
1. 중앙값(median)
중앙에 있는 값, 데이터를 정렬한 뒤 중앙에 있는 값을 의미합니다.
기초 데이터는 정렬이 되어 있는 상태이니 중앙값은 100입니다.
2. 중간범위(midrange)
가장 큰 값과 작은 값의 평균
기초 데이터에서 가장 큰 값은 100 가장 작은 값은 75이므로 100-75/2 가 중간범위가 됩니다
3. 평균
모든 값을 더한 후 개수를 나눈 값
(75 + 80 + 100 + 100 + 100) / 5 가 평균이 됩니다. 91이네요
4. 최빈값(mode)
가장 자주 나온 값
100이 3번으로 가장 많이 나왔습니다. 따라서 최빈값은 100입니다.
5. 범위(range)
가장 높은 점수와 가장 낮은 점수의 차이
가장 높은 점수는 100이고 가장 낮은 점수는 75입니다. 그 둘의 차이는 25로 범위는 25가 됩니다.
6. 분산(variance)
데이터가 평균으로부터 얼마나 퍼져 있는지를 나타내는 지표
분산이 크면 데이터가 평균으로부터 많이 퍼져 있음을 의미하며, 분산이 작으면 평균 근처에 몰려 있음을 의미합니다.
분산이 높다 or 분산이 크다 -> 훈련 데이터에 너무 적합하다(과적합)
7. 편향(Bias)
데이터가 특정 방향으로 치우진 것. 머신러닝에서는 예측이 실제값과 얼마나 다르게 나타나는지를 의미합니다.(모델이 데이터의 패턴을 잘 학습하지 못할 때)
"편향이 크다"는 의미는 모델이 훈련 데이터에 과소적합 될 수 있다는 의미입니다.
ex) 모델이 단순해 복잡한 데이터를 예측 X -> 편향이 크다 -> 과소적합
7-1. 분산 - 편향 트레이드오프(Bias - Variance Tradeoff)
모델의 편향(bias)와 분산(variance) 사이의 균형을 어떻게 맞추는 것
앞에서 분산이 높으면 과적합(overfitting), 편향이 높으면 과소적합(underfitting)이 된다고 했습니다.
그래서 모델의 복잡성이 높아지면 분산은 높아지고 편향은 낮아집니다.
반대로 모델의 복잡성이 낮아지면 분산이 낮아지고 편향은 높아집니다.
좋은 모델은 편향과 분산 사이에 균형을 맞춥니다.
8. 표준편차(standard deviation)
데이터가 평균으로부터 얼마나 떨어져 있는지를 측정하는 척도
값이 클수록 데이터가 평균에서 많이 분산되어 있고, 값이 작을수록 데이터가 평균에 더 가까이 모여 있는 것을 의미
8-1) 표준화(standardization)
머신러닝의 전처리(preprocessing) 기법 중 표준화(standardization)는 데이터를 평균 0, 표준편차 1이 되도록 변환하는 기법입니다.
표준화는 데이터가 "정규분포 형태"를 띌 때 효과적입니다.
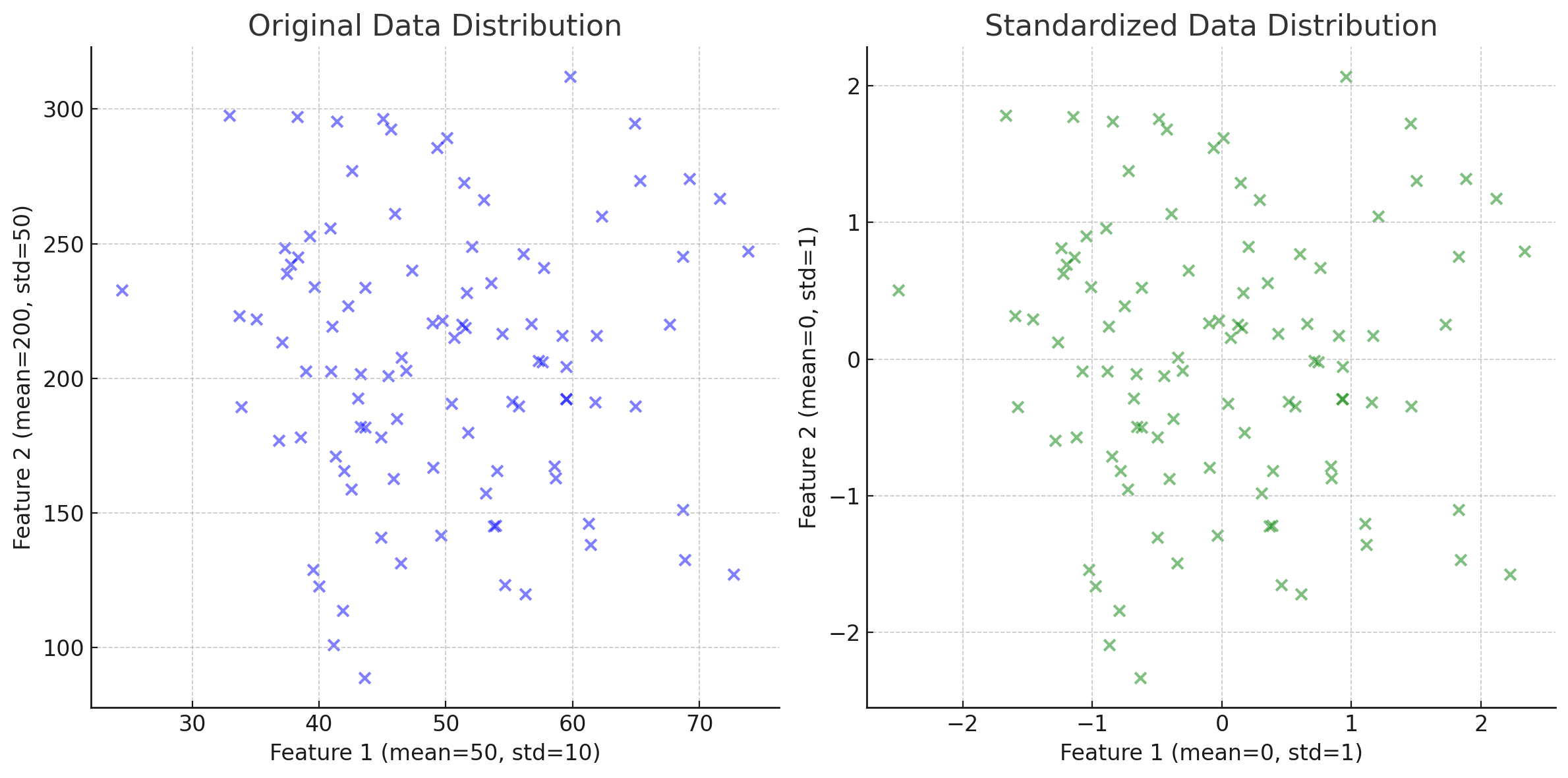
데이터의 분포와 이상치를 유지하면서 각 특성의 스케일을 맞춥니다.
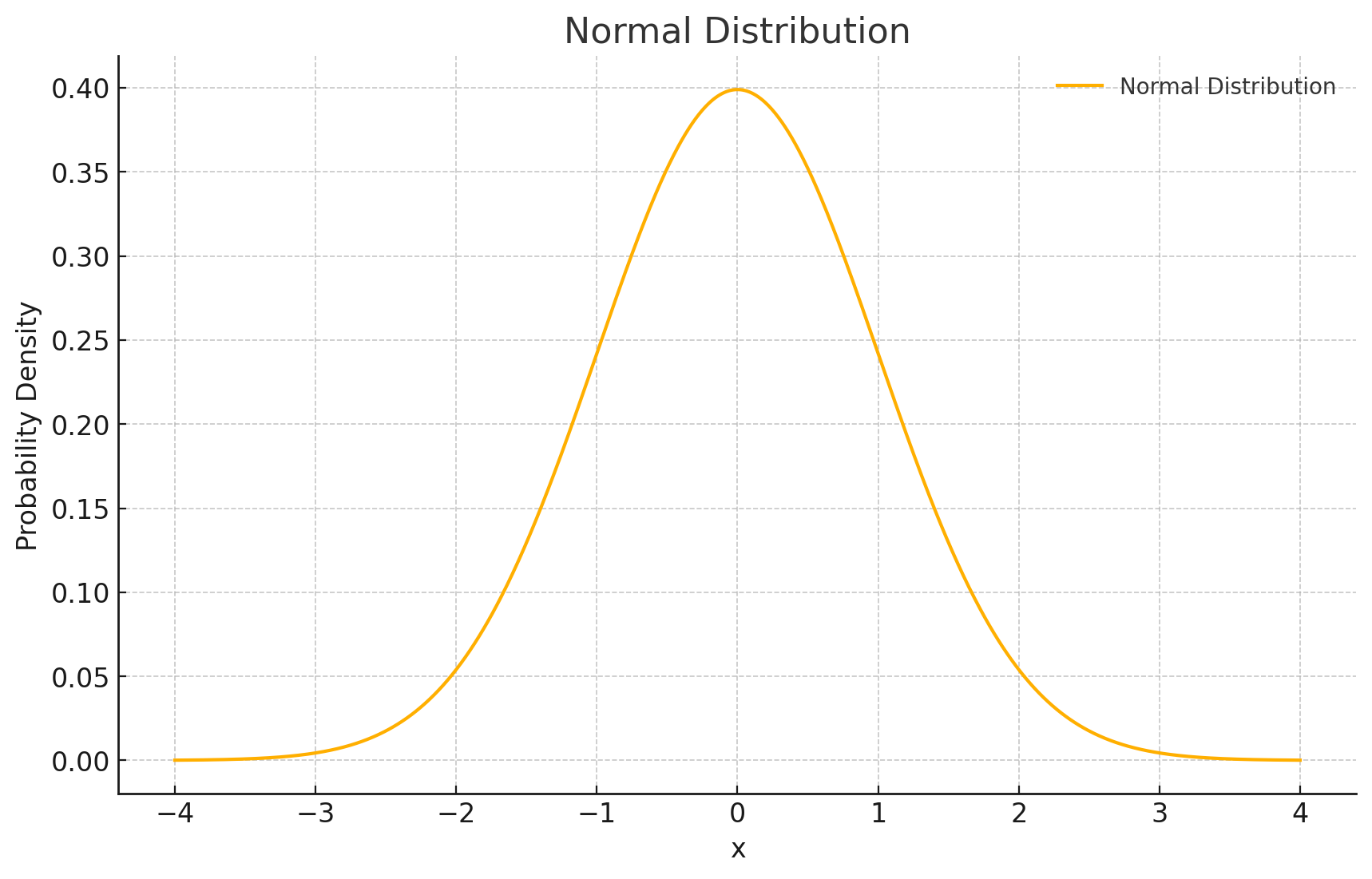
9. 정규분포(Normal Distribution)
데이터가 평균을 중심으로 좌우 대칭을 이루는 종 모양의 분포를 의미합니다. 가우스 분포라고도 부릅니다.
추가) 정규화(Normalization)
표준화를 설명했으니 정규화도 추가해보겠습니다.
대표적으로 min-max 정규화가 있는데 데이터를 0과 1 사이의 값으로 조정하는 방법입니다.
데이터의 범위를 0~1 사이로 만들어 범위가 일정합니다. 단 이상치(outliers)에 민감하며, 극단적인 값이 있으면 정규화의 효과가 떨어질 수 있습니다.
신경망 학습시 유용합니다.
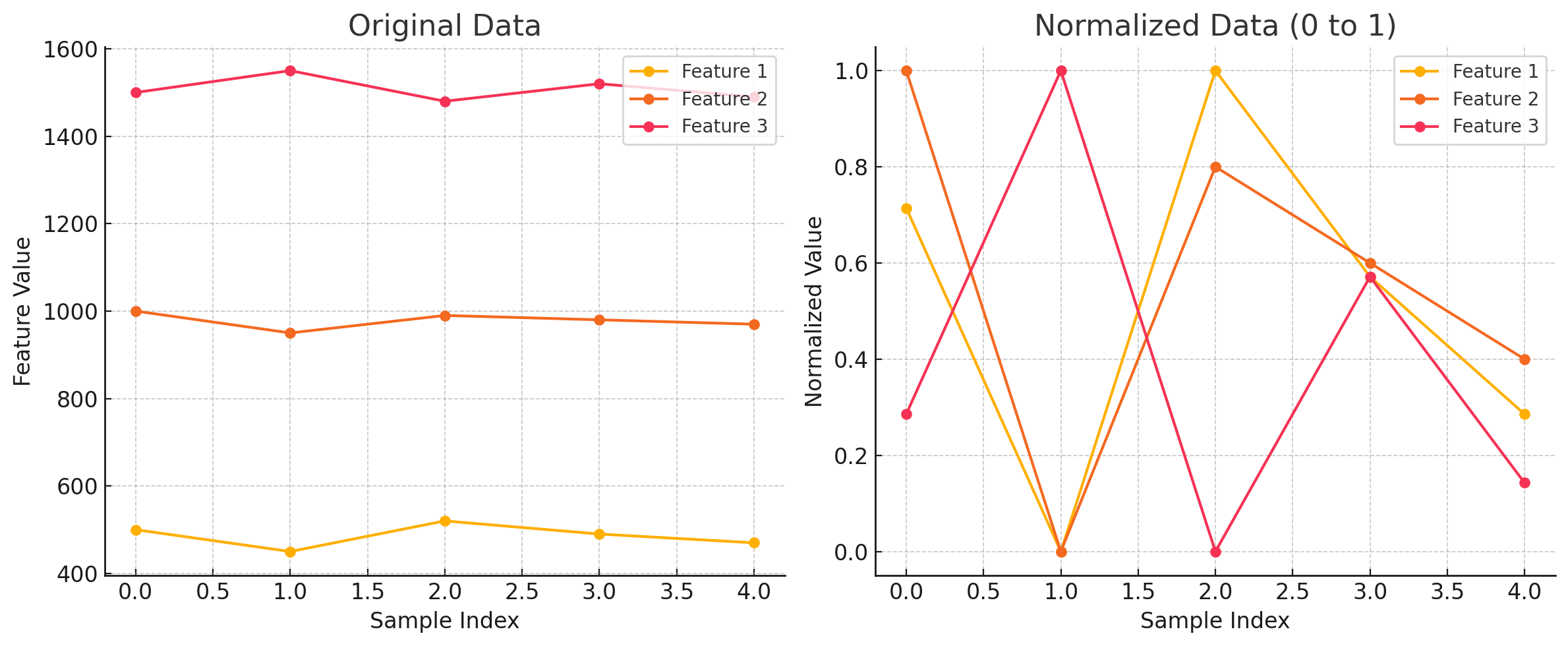
400~1600인 범위가 0~1 사이로 줄여졌습니다.
'[머신러닝]' 카테고리의 다른 글
| [머신러닝] 회귀(Regression) 모델과 성능지표 (1) | 2024.10.27 |
|---|---|
| [머신러닝] 혼동행렬(Confusion Matrix)과 성능지표 (0) | 2024.10.15 |
| [머신러닝] TF-IDF란? (0) | 2024.05.07 |
| [머신러닝] 문장 유사도 분석을 위한 Levenshtein Distance(편집거리 알고리즘) 행렬 구하기 (0) | 2024.04.18 |