![[머신러닝] 혼동행렬(Confusion Matrix)과 성능지표](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F3ZzYv%2FbtsJ6hDNNRX%2FAAAAAAAAAAAAAAAAAAAAAPUFSG2pG0TlGb2NJV6ghXmhilfXUomz92VklB_3eO-d%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DfZ5jKzQcfn0hi3C7ja2QCGgw7n4%253D)
머신러닝 분류 모델의 성능을 평가할 때 주로 사용되는 개념인 혼동행렬과 성능지표들에 대해서 알아보겠습니다. 가끔 보는 내용이라 매번 헷갈리기 때문에 이번에 정리해보려 합니다.
1. 혼동행렬(Confusion Matrix)
혼동행렬(Confusion Matrix)는 다음과 같이 생겼습니다.
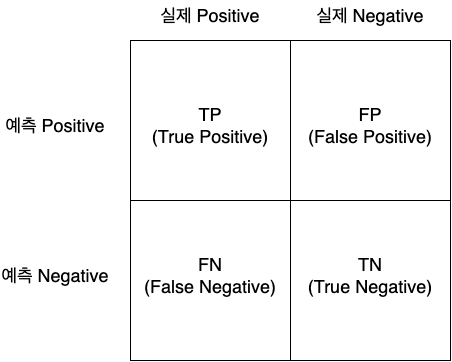
모델이 객체를 분류할 때의 예측한 결과와 실제 결과를 비교하여 분류 모델이 얼마나 잘 작동하는지 보여줍니다.
- TP(True Positive, 참 긍정): 실제 "긍정(True) 클래스"인 샘플을 모델이 "긍정 클래스"라고 정확히 예측한 수
- TN(True Nagetive, 참 부정): 실제 "부정(Negative) 클래스"인 샘플을 모델이 "부정 클래스"라고 정확히 예측한 수
- FP(False Positive, 거짓 긍정): 실제 "부정(Negative) 클래스"인 샘플을 모델이 "긍정 클래스"라고 잘못 예측한 수
- FN(False Negative, 거짓 부정): 실제 "긍정(True) 클래스"인 샘플을 모델이 "부정 클래스"라고 잘못 예측한 수
*TN이라 할때 뒤에 있는 알파벳인 N을 기준으로 모델이 예측합니다. True Negative이니까 부정으로 예측했는데 True니까 실제 값도 부정이다.
FN은 N이니까 부정으로 예측했는데, 실제값은 False니까 긍정이다. FP는 P니까 긍정으로 예측했는데, 실제값은 False니까 부정이다. TN은 N이니까 부정으로 예측했는데, 실제값은 True니까 부정이다.
예를 들어 암에 걸린 환자를 판단하는 모델의 성능을 측정한다고 할 때, 암에 걸린 것을 Positive라 하겠습니다.
그러면 TP는 암이 있는 환자를 모델이 정확히 암으로 예측한 경우가 되고
TN은 암이 없는 환자를 모델이 정확히 암이 없다고 예측한 경우가 되며
FP는 암이 없는 환자를 모델이 암이 있다고 잘못 예측한 경우
FN은 암이 있는 환자를 모델이 암이 없다고 잘못 예측한 경우가 됩니다.
2. 성능지표
이러한 혼동 행렬을 바탕으로 다양한 성능 지표를 계산할 수 있는데 정확도, 정밀도, 재현율, F1-Score가 있습니다. 앞에서 봤던 TP, TN, FP, FN 등을 사용합니다.
1) 정확도(Accuracy): 전체 예측 중 맞춘 비율

전체 데이터에서 모델이 얼마나 잘 예측했는지를 의미합니다.
"데이터 불균형이 적은 상황"에서 사용될 수 있습니다. 예를 들면 암 환자가 1%, 건강한 사람이 99%인 데이터에서는 데이터 불균형이 높은 경우가 됩니다. 이런 상황에서는 정확도가 높아도 모델이 잘못된 결정을 내릴 수 있으므로 정확도는 적절한 지표가 아닙니다.
2) 정밀도(Precision): 긍정으로 예측한 것 중 실제 긍정
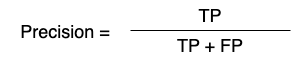
FP(거짓 긍정)을 줄여야 하는 상황에서 사용됩니다. (그래서 분모에 거짓 긍정이 있습니다.) 부정 클래스인데 예측을 긍정 클래스로 잘못 예측한 것을 말하며, 예를 들어 스팸 메일 분류가 대표적입니다. 스팸이 아닌 메일을 스팸으로 잘못 분류하면 안되기 때문에 그렇습니다.
*스팸인 메일(긍정), 스팸이 아닌 메일(부정): 스팸이 아닌 메일(부정)을 스팸 메일(긍정)으로 잘못 분류하면 X
3) 재현율(Recall): 실제 양성 중 얼마나 양성을 잘 예측

실제 긍정 클래인 데이터 중 얼마나 잘 긍정 클래스로 예측했는지 측정
FN(거짓 부정)을 줄여야 하는 상황에서 사용됩니다. (그래서 분모에 거짓 부정이 있습니다.) 암 환자를 건강하다고 잘못 예측하는 것을 최소화해야 하기 때문입니다.
*암 환자(긍정), 건강한 사람(부정): 암 환자(긍정)을 건강한 사람(부정)으로 잘못 예측하면 X
4) F1 Score: Precision과 Recall의 조화 평균

데이터 불균형이 클 때, 정밀도와 재현율 중 어느 하나에 치우지지 않고 균형을 유지하는 모델을 평가하는 데 적합합니다.
5) 특이성(Specificity): 실제 부정 클래스 중에서 모델이 부정 클래스를 정확히 예측한 비율

재현율(Recall)은 실제 Positive를 잘 맞추는 능력을 평가하는 반면, 특이성(Specificity)는 실제 Negative를 잘 맞추는 능력을 평가합니다.
6) AUC-ROC(Area Under the Curve - Receiver Operating Characteristic Curve)
6-1) ROC 곡선
이진 분류 문제에서, 모델의 True Positive Rate(재현율)과 False Positive Rate(거짓양성 비율) 사이의 관계를 시각적으로 표현한 그래프입니다.
TPR: 실제로 긍정인 클래스를 긍정 클래스로 예측한 비율, 즉 재현율입니다.
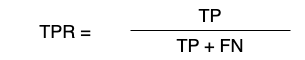
재현율(Recall)과 같습니다.

FPR: 실제 부정 중에서 모델이 잘못 긍정으로 예측한 비율입니다.
왜 TPR, FPR인가?
재현율(TPR)은 모델이 긍정 클래스를 얼마나 잘 예측하는지를 측정하고, FPR은 모델이 부정 클래스를 얼마나 잘 구분하지 못했는지 측정합니다.
ROC 곡선은 모델이 임계값(threshold)을 변화시킬 때, 재현율과 FPR의 변화를 보여준다고 했습니다. 이 말은 즉, 모델이 양성 클래스를 얼마나 잘 맞추는지(재현율)과 음성 클래스를 얼마나 잘 구분하는지(FPR)를 동시에 평가할 수 있습니다.
그래서 아래 그림을 보면 빨간색 그래프가 가장 성능이 좋은데 TPR은 높고 FPR은 낮습니다.
*TPR이 높다는 것은 양성 클래스를 잘 예측한다는 뜻이고, FPR이 낮다는 것은 음성 클래스를 양성 클래스로 예측하는 비율이 낮다는 것을 의미합니다.

좌상단에 붙어 있을 수록 성능이 좋은 이진 분류기 입니다.
사진 속 점선으로 표현된 45도 각도의 선은 랜덤으로 이진분류를 한다는 의미입니다. 그렇게 화살표 방향으로 갈수록 성능이 좋아집니다.
6-2) AUC(Area Under the Curve)
AUC는 ROC 곡선 아래 면적을 의미하며 0과 1 사이의 값을 가지는데 값이 1에 가까울수록 모델의 성능이 우수함을 의미합니다.
위 사진에서 점선으로 표시된 성능을 가지게 되면 랜덤으로 예측하는 것과 동일한 성능이라고 말씀드렸습니다. 45도 각도의 선을 가진 ROC 곡선의 넓이는 가로1, 세로1이라 할때 1/2이기 때문에 AUC가 0.5이면 랜덤한 성능을 가진다고 말합니다.
반대로 ROC 곡선이 왼쪽 상단으로 치우쳐질 수록 높은 성능을 가지게 되는데 AUC는 0.5 이상의 값을 가지게 됩니다. 최대가 1이며 0.5에서 1에 가까울 수록 완벽에 가까운 이진분류기 성능을 보여준다고 말할 수 있습니다.
AUC가 0.9 ~ 1이면 매우 우수한 성능의 분류 능력을 보여준다고 할 수 있습니다.
0.5 ~ 0.7 사이의 AUC를 가지면 분류 성능이 낮으며, 성능 개선이 필요한 수준입니다.
'[AI]' 카테고리의 다른 글
| [딥러닝] 인공신경망(ANN)의 작동 원리 완전 정리: 순전파부터 역전파, 활성화 함수까지 (3) | 2025.08.04 |
|---|---|
| [머신러닝] 회귀(Regression) 모델과 성능지표 (1) | 2024.10.27 |
| [머신러닝] TF-IDF란? (0) | 2024.05.07 |
| [머신러닝] 문장 유사도 분석을 위한 Levenshtein Distance(편집거리 알고리즘) 행렬 구하기 (0) | 2024.04.18 |
| [통계] 중앙값, 중간범위, 평균, 최빈값, 범위, 표준편차, 정규분포, 편향, 분산 (0) | 2023.07.15 |